The geography of my mind is the geography of the world I walk in.
John Moriarty, Dream Time. 1994
Learning to use a new language model can be difficult. Output from Generative AI can be unpredictable, and learning how to navigate the quirks of a model can be a time consuming process. Other creative tools, like Figma, dedicate significant resources to designing for user learning, creating skill ramps that help build tool proficiency. Why wouldn't AI take a similar approach? A big reason is that language models are black boxes. You don't know what's going on under the hood of a model. Trial and error is the only way to gain feedback.
But what if generative AI interfaces were able to let the user peek under the hood? This would both reduce the friction of onboarding and enable more accurate prompt output. More fundamentally, helping users understand how a model interprets a prompt will shift the paradigm of how we interact with generative AI. Seeing into the workings of the black box invites users into the process, helping them understand the why behind an output. Crucially it provides additional touchpoints for user control and feedback.
How can we see into the black box of a language model? The answer may come from a recent a paper published by Anthropic called "Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet". This paper applied a technique called dictionary learning to map features from Anthropic's medium-sized production model. This approach allowed the researchers to map the proximity of features across the entire model.

Header image from Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Features are conceptual groups created by the model, which correspond roughly to topic areas. These include features for cities, landmarks, famous people, but also cover concepts and categories such as "Christian virtues", and "famous female pilots." There's a great feature explorer that allows you to navigate "feature neighborhoods" yourself. Features have some interesting emergent characteristics. From the paper:
Many features are multilingual (responding to the same concept across languages) and multimodal (responding to the same concept in both text and images), as well as encompassing both abstract and concrete instantiations of the same idea 1
Most importantly, the researchers proved that this process is scalable, and while resource intensive, could be applied to larger production models. The focus of this paper is on AI safety, using the mapping methods developed by the researchers to better understand bias and potential risk areas. Yet the scalability of a dictionary mapping approach to feature proximity also has significant applications for UX.
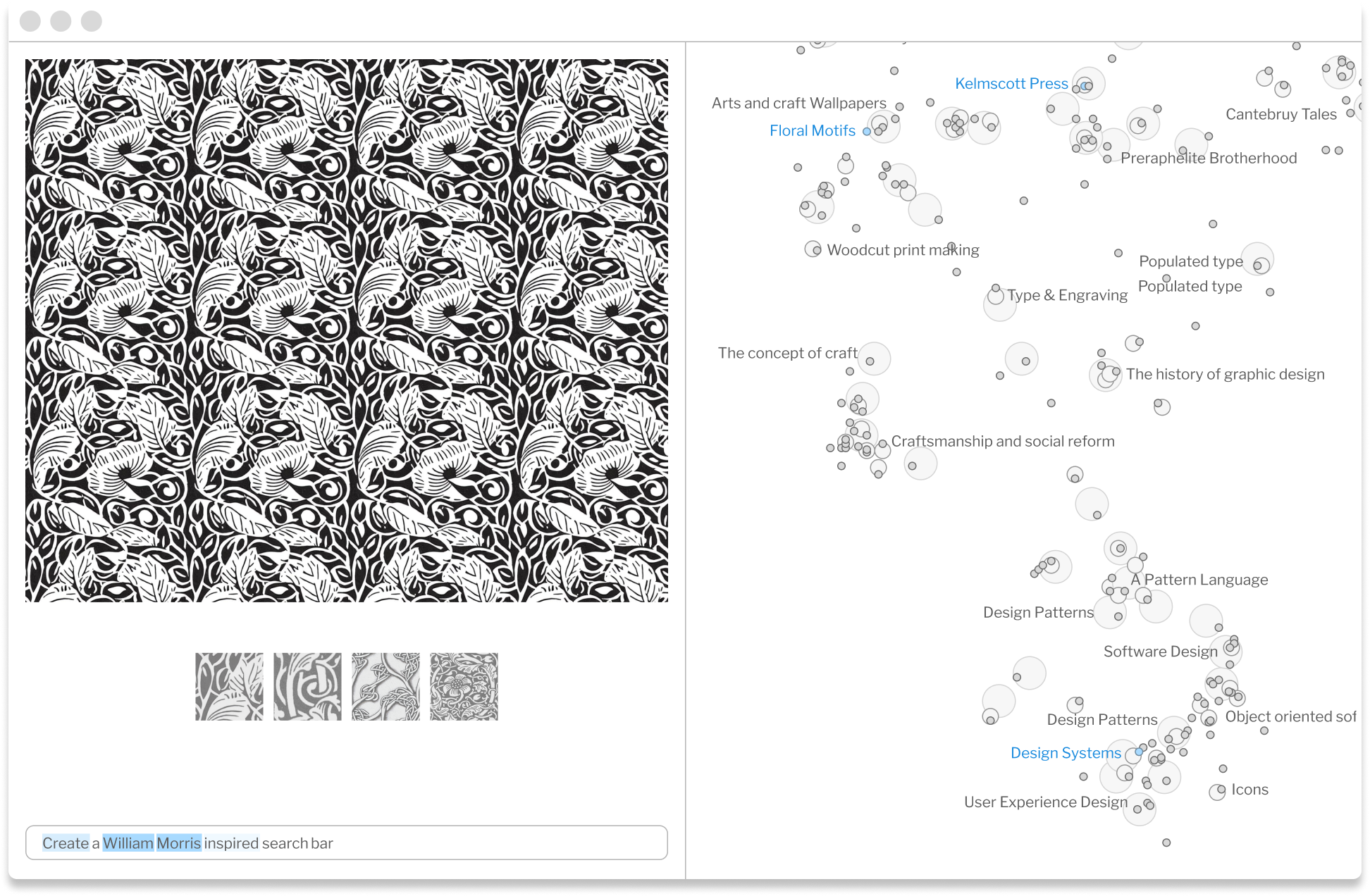
Recently I was researching William Morris. I was curious what a William Morris inspired search bar might look like, so I tried to prompt this. The results were unimpressive. The connection was too tenuous, I decided. Though I didn't have any direct insight into the model I was using, it was clear that my intention was not being articulated in a way that was meaningful to the model. I tried a few more prompts, but saw little improvement.
Let's imagine a different outcome. I'm using a UI that surfaces a feature map of the model I'm prompting. When I submit a prompt, I'm shown the topic areas I've activated, and I have the ability to explore the associated feature neighborhoods.

I also see a heat map, showing how closely words in my prompt are associated with the feature areas I am exploring. I can click associated features in the neighborhoods, mapping a path across the concepts I want to trigger.
After selecting different feature areas, the prompt is rerun, giving me direct feedback into the impact those feature areas had on the output. Through this process, I'm able to incorporate additional specificity and meaning I hadn't even considered at the start.
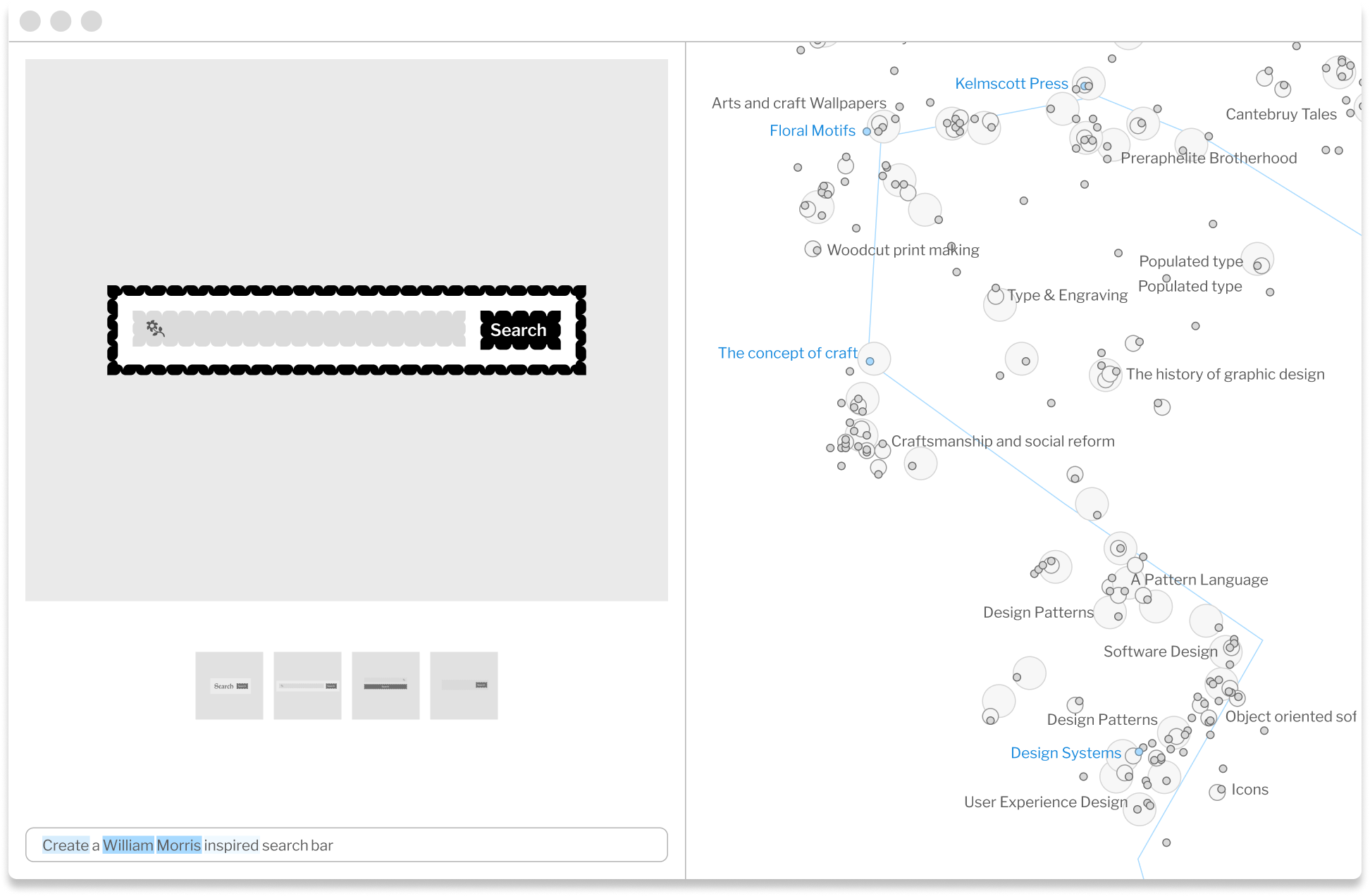
These mockups gesture towards what is possible. While the map is limited to two dimensions, it is likely that being able to navigate in n dimensional space would be required to traverse the feature space in a meaningful way. However, how to accomplish n dimensional navigation in a two dimensional UI is a topic for another essay.
Despite these challenges, this is a user experience that not only affords greater feedback, but also asks the user to participate in the process of creation. Rather than having the model "think" for the user by magically generating an output, surfacing a transparent map of the model can help users see the areas activated. The user is now involved in an otherwise obscure process, employed as a navigator. The output become concrete user feedback, resulting in not only a more convivial human computer relationship, but also the potential for more significant and meaningful outputs.
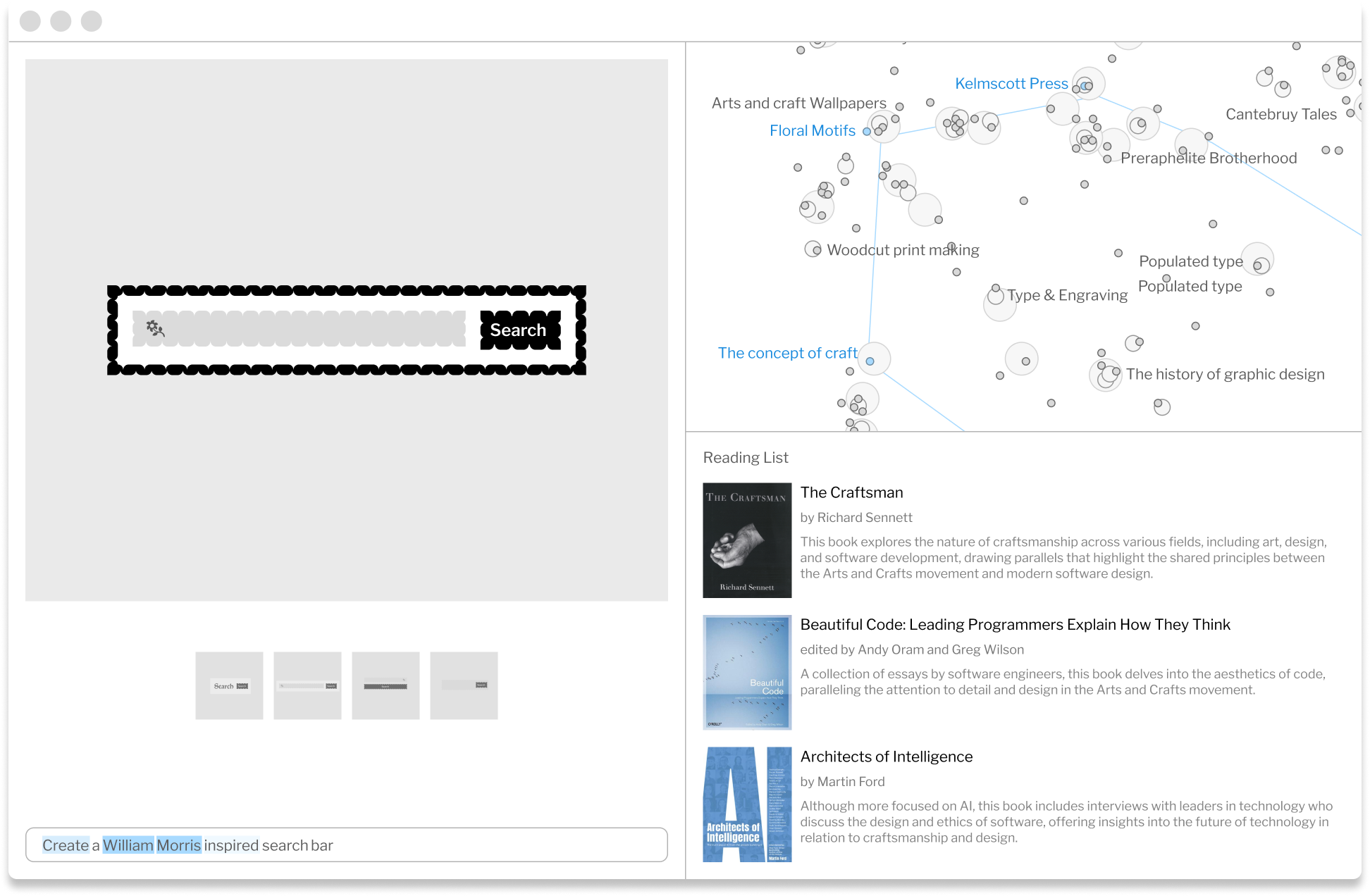
When I was prompting a William Morris inspired search bar, I didn't know what the connection was. I hadn't fully thought it through yet. All I had was an intuition that there was an intriguing through-line that I didn't quite understand. I hoped that something from the output of my prompt would spark an insight into the unexpected collision I was exploring. Imagine: in addition to navigating topic neighborhoods, I could also generate a reading list or mood board from each feature. Features could be used to help guide further research, helping point to significant concepts, topics, and works. Being invited into the the output process and nudged to consider the line of connection could shift the paradigm of prompting, creating a flow for generative AI that is more thoughtful, meandering, and reflective. Learning and deeper inquiry become more effortless.
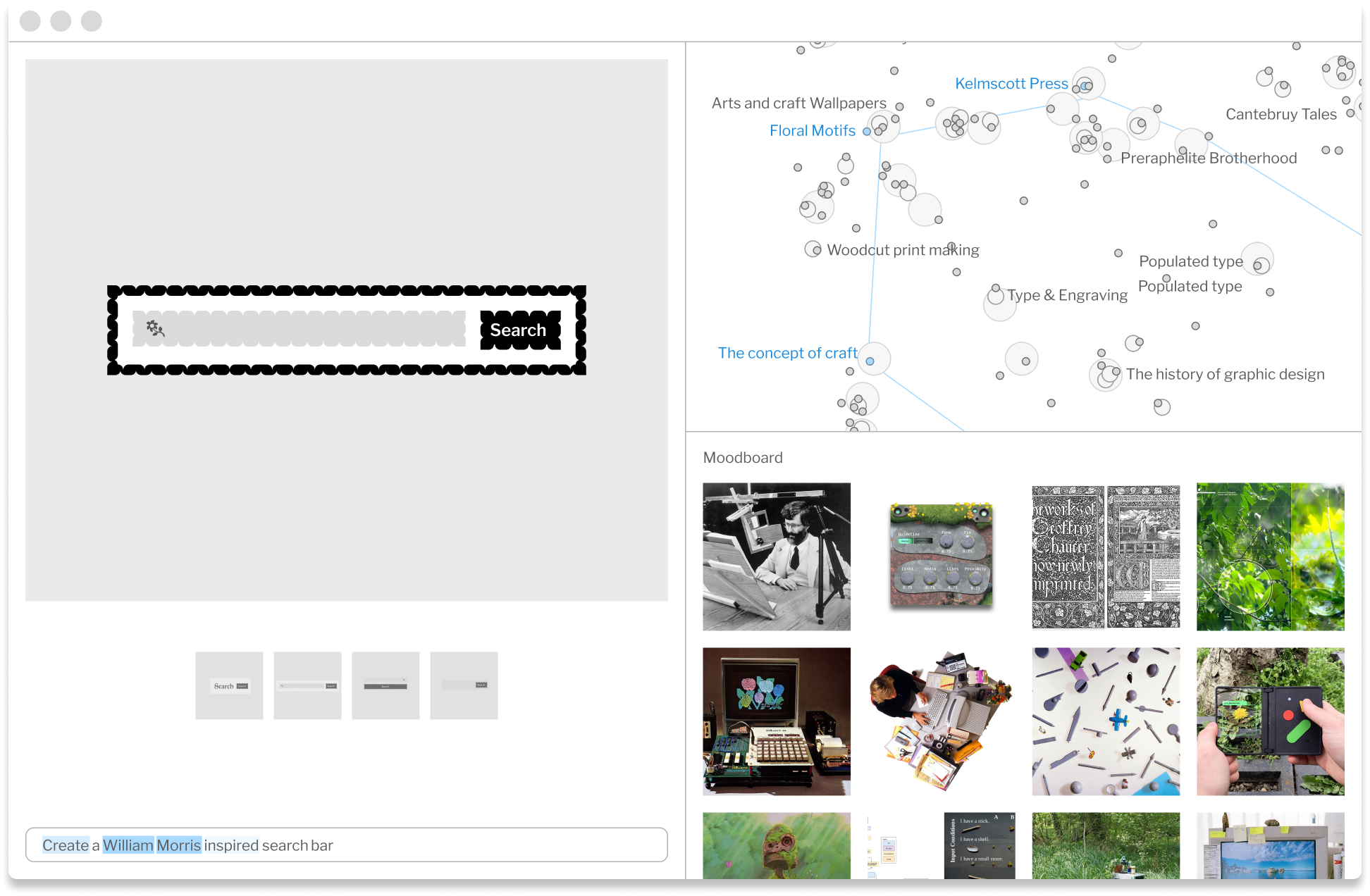
As generative AI matures, we have the opportunity to fundamentally change how we engage with these tools. Turning what was once opaque into a transparent interaction will not only lead to better outputs and faster onboarding but also positively transform human-computer interaction. By offering users the ability to explore the features of the language models they use, we introduce affordances for greater specificity and more intuitive feedback, fostering a thoughtful, exploratory user journey driven by curiosity, creativity, and connection.
Better AI doesn't just mean more powerful models. It also means better interfaces that enhance user agency. Mapping models will help to create a more informed and knowledgeable user-base, opening the door to exploration and serendipity. In the place of a black box, we have an opportunity to create a user experience that not only lets users see under the hood, but rewards their exploration. Instead of a glimmering wand icon, conjuring an output from nothing, we can give user something much more magical: the ability to navigate vast knowledge networks charted as features within a language model.
Footnotes
-
Templeton, A., & Conerly, T. (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Anthropic. https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html ↩
Read More
Read More
Get Updates
© 2025